Abstract: We describe an approach to personalizing World-Wide Web navigation that combines ideas from social filtering and social navigation. Specifically, we propose a method for (a) automatically finding the boundaries of user communities by clustering users around web places, which we define as locations in web space that are bound together by common usage patterns; and then (b) adapting what web users see to the places community members congregate. We describe our implementation of web places based on the Web Browsing Intermediaries (WBI) framework (Barrett, Maglio, & Kellem, 1997; Barrett & Maglio, 1998), and suggest future work to help judge its utility.
Keywords: World-Wide Web, personalization, user modeling, social navigation, social filtering.
The holy grail for designers of information delivery systems is to find a mechanism for automatically determining user interests, thus enabling adaptive information delivery. For the World-Wide Web (WWW), this means finding ways to suggest web pages that are interesting and relevant to web users. One promising approach is social filtering, in which individual user interests are determined indirectly by clustering users into groups with common interests (Goldberg, Nichols, Oki, & Terry, 1992; Maes, 1994; Resnick & Varian, 1997). The key problem in social filtering systems lies in grouping users. Some systems rely on explicit voting or selection of information items or categories to derive the user profiles that are then clustered (e.g., Konstan, Miller, Maltz, Herlocker, Gordon, & Riedl, 1997; Shardanand & Maes, 1995). Other systems are more passive, relying on ordinary user actions or existing information to derive profiles used to cluster users into groups (e.g., Rucker & Polanco, 1997). Thus, social filtering relies on a community to determine what is appropriate, but members of the community generally do not interact directly in forming judgements.
By contrast, social navigation refers to cases in which individual users explicitly make recommendations when interacting with others (Dieberger, 1997; Gruen & Moody, 1998; Maltz & Ehrlich, 1995). For social navigation systems, designers do not build in mechanisms for automating information delivery; rather, members of a user community interact directly to deliver information to one another. The main design problem is to provide appropriate affordances to promote information sharing.
In this paper, we suggest an approach to adaptive information delivery that combines ideas from social filtering and social navigation. From social filtering, we take the idea of automating information recommendations using communities bound by common interest. From social navigation, we take the idea that communities naturally grow by interacting on a topic of common interest. Specifically, we propose a method for finding the boundaries of user communities by clustering users around web places. We define a web place as a location in web space that is bound together by usage patterns common to a collection of users. Given that users congregate around web places, we describe a method for adapting web pages to the interests of community members.
In what follows, we describe our approach in some detail. We first discuss the idea of web place, and then present our architecture and implementation. In the final section, we suggest follow on work to test the utility of this approach.
Although people naturally think of the WWW as a kind of physical space in which they move to obtain information (Maglio & Matlock, 1998), they do not seem to think of the web as a kind place where they might meet and interact with others. Of course, the reason is because users on the web generally interact only with information. So what makes a place? In the context of human-computer interfaces, Erickson (1993) defines place as space plus meaning, and Harrison and Dourish (1996) define it "as space which is invested with an understanding of behavioral appropriateness, cultural expectations, and so forth" (p. 69). Thus, a sense of place derives from a shared understanding about a space, and interpersonal interactions are critical in creating shared understanding.
In the simplest case, a single web page might serve as a web place where groups of individuals gather to discuss matters related to the page's topic. For instance, the home page of a particular organization, such as IBM research, could be the focal point for discussions about that organization, such as technology for copper chip fabrication. Or a web page advertising prices on a certin model of computer would be a great place to find people knowledgeable about where to get the best deals on that kind of computer. The key point is that a place provides a context for human interaction. But unlike a coffeehouse, where people gather because of its proximity to home or the taste of the coffee it brews, the information-rich environment of the web naturally provides contexts bound by interest or information.
The WebPath browser (Gruen & Moody, 1998) goes some way toward helping to establish larger places on the web where people can interact. Users start by following a predefined path, such as a path for the morning's news or for learning about snowboarding. Once on the path, the browser application enables users to see where others are browsing, to chat with others while browsing, and to follow another user in real-time. The key idea here is that a community of users gathers around a predefined path, establishing conventions and understandings of the information on the path or related to the path by directly interacting with each other.
Chalmers, Rodden and Brodbeck (1998) describe a method for automatically calculating places on the web where people actually congregate. More precisely, they describe a system that uses web interaction histories of groups of users to determine whether a particular user is travelling a well-worn path. Using this information, their system can suggest further nodes to follow given the previously worn trails as a guide. In this case, communities of users develop naturally around meaningful clumps of information, which are then used to guide information exploration.
Our idea of a web place incorporates both deliberate user-user interaction as well as automatic clustering of users by information usage patterns. In addition, we believe that the most effective way to give users a sense of place is through the web page itself (see Barrett, Maglio, & Kellem, 1997, for a discussion of our general design guidelines). Rather than adding features to the browser or using a separate application window, our system actively adapts the form and content of web pages to the communities that view them. In particular, we modify web pages on the fly to enable interaction with other users, and we provide new web functions (i.e., special URLs) for keeping tabs on and for communicating with other users as well.
Our Web Places system transforms web pages into web places by annotating web pages with information about some of the other users who are currently or who have recently followed the same trail. One annotation adds to the bottom of the page links to these other users, along with comments they have made about the page. The links to these other users provide the means for finding out more about them, such as where they have been, as well as for chatting with them or for following them. In addition, users themselves can annotate pages, leaving notes or comments that others can see or even add to.
Another way that Web Places annotates pages is by providing hints on which links to follow. Our approach to calculating these suggestions is similar to that of Chalmers, Rodden and Brodbeck (1998), that is, in terms of the worn trails. We are experimenting with several methods for displaying these: (a) suggested links can be listed at the top of the page, providing explicit suggestions; and (b) the links embedded in the text of the page can be effectively annotated with small images to subtly direct users' attention to some links over others (Campbell & Maglio, 1998).
As an alternative to relying on automatic adaptive communities, Web Places also allows users to define their own communities. For example, if a user meets someone in an adaptive community, they can be added to one another's list of friends. Such groups of user-defined friends form a communities that are not confined to a particular Web Place. Whenever someone is using the web, their friends can contact them, find them in whatever Web Place they happen to be exploring, or chat with them. These user-definable communities are similar to environments such as ICQ.
In addition to annotating pages, Web Places provides web pages that allow users to survey the communities of users actively browsing the web. Whereas Gruen and Moody's (1998) WebPath browser bases its notion of community on the set of users following a predetermined path, our system can coordinate several communities whose boundaries are determined on the fly. One benefit of the WebPath approach is that there is a reasonable expectation that some set of users would be following a predetermined path, and so a community would likely exist. For Web Places, communities are determined by the paths users actually travel, and so there is no guarantee others will follow similar trails. We think the key to making Web Places work lies in constraining the larger set of users connected by the system to some natural community, such as researchers at IBM or members of a university computer science department. If the larger community is too broad, then there will be insufficient commonality from which to derive communities. We return to this issue in the final section.
In the next section, we describe the architectural framework behind our Web Places implementation.
Intermediaries are computational elements that lie along the path of web transactions (Barrett & Maglio, 1998). They may operate on web data as the request is sent from the browser, passes through firewalls and proxies, is satisfied by the generation of a document, and as the document is returned to the browser. Intermediaries have access to web data at all these points, and are able to observe, respond to requests, and modify both the request and the resulting documents. Our intermediary architecture, Web Browser Intermediaries (WBI), is a programmable proxy server that was designed for easy development and deployment of intermediary applications.
In WBI, intermediary applications are constructed from five basic building blocks: request editors, generators, document editors, monitors, and autonomous functions. We refer to these collectively as MEGs, for Monitor/Editor/Generator. Monitors observe transactions without affecting them. Editors modify outgoing requests or incoming documents. Generators produce documents in response to requests. Autonomous functions run independently of any transaction and perform background tasks. WBI dynamically constructs a data path through the various MEGs for each transaction. To configure the route for a particular request, WBI has a rule associated with each MEG that specifies a boolean condition indicating whether the MEG should be involved in a transaction. An application is usually composed of a number of MEGs that operate in concert to produce a new function.
The first application we constructed with WBI was personal history, which uses a monitor that records the sequence of pages visited by each user along with the text of each page (see Barrett, Maglio, & Kellem, 1997). The user can access his or her own personal history through generators that search through the stored text or that display paths taken previously. In addition, the markup of individual pages can be changed to reflect patterns of repeated use, for instance, adding shortcut links to pages that are visited repeatedly within some radius of the current page. We also experimented with a WBI application to cluster a user's history of web usage around key nodes found on the way to some goal (Maglio & Barrett, 1997). In all cases, we were concerned with supporting the web navigation of individual users by providing access to the user's own web history in expected and natural ways. The key point is that the way the web looks to an individual user can be adapted based on the user's history of interactions with the web.
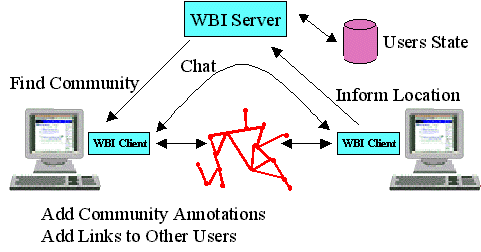
Our implementation of Web Places takes these kinds of adaptations one step further by using the web histories of a community to change the way the web looks to individuals. We used WBI to implement both a client proxy that runs on an individual user's machine as well as a server that runs on another machine to which all users have access (see Figure 1). On each web transaction, the WBI client uses an editor to modify the returned document to include link annotations and links to people on the same trail. To do this, the WBI client communicates with the WBI server to find out whether there is a community of users around the current page. The server keeps track of all users trails and performs a simple subtrail match with some maximum length (such as five nodes) to determine whether there are common subtrails. If there are, the set of users on the common trail is reported back to client, along with information about which links were most frequently followed. The WBI client uses this information to annotate the current page. Chat is done through a Java applet that the client also embeds in the page. The applet contacts the WBI server through the client to pass text from user to user. In addition to web page annotation, the WBI client also relies on generators to create web pages in response to requests for state information. Again, the client contacts the server to obtain the web locations of other users.
Our work with adaptive communities has just begun. The Web Places implementation provides a framework for experimenting with (a) algorithms for forming communities, (b) methods for adapting hypertext documents to individual community members, and (c) schemes for setting up populations from which communities can be formed. We discuss each of these in turn.
As mentioned, our first algorithm for partitioning users into communities is based on finding users with overlapping subtrails. Various parameters can be set on this algorithm, including the percentage of trail matched, the number of other users who must match, how heavily to weigh current browsing habits relative to previous habits, and so on. In addition, other information might be taken into account when forming communities. For instance, the sort of information contained on a user's hard disk, such as email or papers (Nardi, Miller, & Wright, 1998), or the sorts of activities a user routinely performs on his or her own computer, such as applications used and their frequency (Underwood, Maglio, & Barrett, 1998), can be combined with web usage to create a more elaborate and more detailed user model. In any event, as the number of users increases and the length of user trails increase, tradeoffs of computational efficiency will undoubtedly become another issue to investigate.
Following the general design principle of personalizing the web by tailoring it to individual users (rather than by adding additional windows or functions), we have described several simple methods for annotating hypertext to create web places, including adding links to track users on the same trail, and annotating links that previous users have followed. Another method for adapting what users see is to change the connectivity of the web (Brusilovsky, 1996). In this case, for example, we might remove links that no one has followed previously. In general, we prefer the subtler method of annotating links to this kind of heavy-handed approach. Nevertheless, in certain circumstances, such as instruction or for children, adapting the link structure might make sense. In any event, a wide range of possible methods for adapting form, content, and connectivity based on changing communities have yet to be investigated.
Finally, the most interesting questions from a social perspective revolve around whether adaptive communities can in fact take root. What does it take to have a community that people actually want to invest in? Can a meaningful chat result from faceless users gathered around a web page? Or must people have a prior history of involvement? Can computers help form interpersonal groups and web-pals that are persistent, lasting longer than the time it takes to click through a single page? To be sure, chat is extremely popular, and persistent interpersonal communication among faceless individuals occurs all the time on the Internet (Turkle, 1995). However, it is not clear that the same will hold true for adaptive communities. As mentioned, we think that making adaptive communities work on a large scale will require constraining the population that use the same Web Places server to one with a broad common interest, such members of the same university department. It is possible, of course, that no such constraint is necessary. For now, this remains an open question.
Barrett, R. & Maglio, P. P. (1998). Intermediaries: New places for producing and manipulating web content. Seventh International World Wide Web Conference, Brisbane, Australia.
Brusilovsky, P. (1996). Methods and techniques of adaptive hypermedia. User Modeling and User-Adapted Interaction, 6, 87-128.
Campbell, C. S. & Maglio, P. P. (1998). How to facilitate information navigation without disrupting perception. Manuscript submitted for publication. IBM Almaden Research Center.
Chalmers, M. Rodden, K. & Brodbeck, D. (1998). The order of things: Activity-centered information access. Seventh International World Wide Web Conference, Brisbane, Australia.
Dieberger, A. (1997). Supporting social navigation on the World Wide Web. International Journal of Human-Computer Studies, 46, 805-825.
Erickson, T. (1993). From interface to interplace: The spatial environment as a medium of interaction. In A. U. Frank & I. Campari (Eds)., Spatial information theory: A theoretical basis for GIS, Berlin: Springer-Verlag.
Goldberg, D., Nichols, D. Oki, B. M. & Terry, D. (1992). Using collaborative filtering to weave and information tapestry. Communications of the ACM, 35, 61-70.
Gruen D.& Moody, P. (1998). Synchronous WebPath as a tool for leveraging expertise. Paper presented at Human Computer Interaction Consortium Conference, Snow Mountain Ranch, CO.
Harrison, S. & Dourish, P. (1996). Re-placing space: The roles of place and space in collaborative systems. Computer Supported Cooperative Work ’96, Cambridge, MA.
ICQ - The world's largest online communication network. Available as http://www.icq.com.
Konstan, J. A., Miller, B. N., Maltz, D., Herlocker, J. L., Gordon, L. R., & Reidl, J. (1997). GroupLens: Applying collaborative filtering to usenet news. Communications of the ACM, 37, 77-87.
Maes, P. (1994). Agents that reduce work and information overload. Communications of the ACM, 37, 31-40.
Maglio, P. P. & Barrett, R. (1997). How build modeling agents to support web searchers. Proceedings of the Sixth International Conference on User Modeling. New York: Springer Wien.
Maglio, P. P. & Matlock T. (1998). Metaphors we surf the web by. Workshop on Personalized and Social Navigation in Information Space, Stockholm, Sweden.
Maltz, D. & Ehrlich, K. (1995). Pointing the way: Active collaborative filtering. Proceedings of Human Factors in Computing Systems, CHI '95. New York: ACM Press.
Nardi, B. A., Miller, J. R. & Wright, D. J. (1998). Collaborative, programmable intelligent agents. Communications of the ACM, 41, 96-104.
Resnick P. & Varian, H. R. (1997). Recommender systems. Communications of the ACM, 40, 56-58.
Rucker, J. & Polanco, M .J. (1997). Siteseer: Personalized navigation for the web. Communications of the ACM, 40, 73-75.
Shardanand, U. & Maes, P. (1995). Social information filtering: Algorithms for automating "word of mouth". Proceedings of Human Factors in Computing Systems, CHI '95. New York: ACM Press.
Turkle, S. (1995). Life on the screen: Identity in the Internet. New York: Simon and Schuster.
Underwood, G. M., Maglio, P. P. & Barrett, R. (1998). User-centered push for timely information delivery. . Seventh International World Wide Web Conference, Brisbane, Australia.