Fabio A. Asnicar, Carlo Tasso
Laboratory of Artificial Intelligence
Department of Mathematics and Computer Science (http://www.dimi.uniud.it/)
University of Udine (http://www.uniud.it/)
Via delle Scienze 206, I-33100 Udine (Italy)
Phone: +39-432-558449; FAX: +39-432-558499
E-mail: tasso@dimi.uniud.it
http://www.dimi.uniud.it/~tasso/
Abstract: This work describes the ifWeb system, a prototype of user model-based intelligent agent capable of supporting the user in the navigation in the World Wide Web, the retrieval and filtering of documents taking into account the specific information needs of the user.
The prototype has been evaluated in order to assess the quality of support, and to compare its performance with analogous systems. The results achieved show that the use of sophisticated user modeling techniques can improve the performance of intelligent agents accessing the Web, and point out interesting challenges for future investigations.
Keywords: information filtering, user modeling, intelligent agent, World Wide Web, autonomous navigation, recommendation service.
The World Wide Web (WWW) is constituted by hypermedia documents which allow accessing the information in a non-linear way (called navigation) through hypertextual links. The huge amount of documents present in the WWW, and the high frequency of their updating, modification and deletion, makes the retrieval of information through navigation a very difficult and heavy operation both in terms of time, complexity and quality of results.
These considerations highlight the usefulness of tools capable of satisfying a user information request by avoiding as much as possible low level tasks: the user is then allowed to freely express his information need in conceptual terms and all the technological details related to network access and search become transparent.
This work describes the ifWeb system, a prototype of user model-based intelligent agent capable of supporting the user in the navigation in the WWW, the retrieval and filtering of documents taking into account the specific information needs of the user.
The most common tools currently used for information retrieval in the WWW are the indexing agents which are based on huge inverted indexes periodically updated (AltaVista, ExCite,...).
More sophisticated tools for retrieving documents in the WWW are based on the exploitation of a user profile. Several proposals can be found in the literature, which include classifiers (Syskill & Webert [1]), tour guides (LAW [2]), diff-agents (Amalthaea [3]) and recommendation services (FAB [4]). All of them share some basic limitation: the technique used to represent knowledge in the user model is based on simple lists of keywords and consequently the algorithm for evaluating the relevance of the document with respect to the user model is based on keyword matching; the kinds of the considered knowledge are very limited, usually restricted to single words, or to (some) structural characteristic or part of the documents; the learning capabilities are usually very poor, if any; the navigation strategies, if any, are usually based on very heuristic criteria; and finally all those systems have been scarcely evaluated and cannot be well compared one to the other.
The ifWeb system is a supporting system: it offers support to the user for executing specific tasks, without imposing specific solutions and/or decisions.
ifWeb is characterized by two modes
of operation. The first one is called navigation support:
from a specific document pointed out by the user it starts an
autonomous navigation, it collects WWW documents, it analyses
and classifies them and, as a result, it shows graphically to
the user the structure of the hypertextual links present in the
documents which have been accessed.
The second mode of operation is called
document search: from a specific document pointed out by
the user, the system autonomously performes an extended navigation
in the WWW, retrieves
and classifies documents. As a result, the system shows to the
user the set of the documents which have been classified as the
most relevant ones, ordered downward from the most interesting.
Both the classification and the navigation strategies are based on the content of the user model, which includes concepts which represent both the interests and the non-interests of the user. More precisely, the model is constituted by a set of attribute-value pairs corresponding to the structured part of the documents (host, size, number of images,...), and a weighted semantic network whose nodes correspond to terms (concepts) found in documents and where arcs link together terms which co-occurred in some document. The exploitation of the semantic network and the use of the co-occurrence relationships allow to overcome some basic limitation of simple keyword matching such as polisemy [6].
The user model is updated and refined by implicit relevance feedback provided by the user: ifWeb extracts autonomously from the documents on which the user explicitly expressed some (positive or negative) feedback, all the information necessary to update the user model. Moreover, ifWeb includes a mechanism for temporal decay, which lowers the weights associated with concepts which have been included in the model and are untouched by the relevance feedback mechanism since a long time. This mechanism allows to maintain the model in such a way that it always represents the cooler interests and non-interests of the user.
ifWeb is organized into several Agencies according to the weak agency notions by Jennings [5].
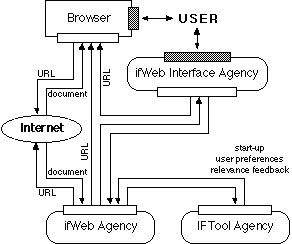
Figure 1 describes the functional
architecture of ifWeb which includes the following modules: the
ifWeb Interface Agency which manages all the interaction with
the user; the ifWeb Agency which performs the specific function
of navigation support and document search; the IFTool Agency which
executes the function of user modeling and is capable of comparing
the document currently analyzed with the user model. This last
Agency is based on the IFTool [6] system and on the user modeling
shell UMT [7].
The Browser provides standard navigation
capabilities and allows to visualize Web documents. The only requirement
for the Browser is its capability to support Java applications,
since ifWeb is implemented in this language.
Figure 2 describes the internal architecture of ifWeb Agency which includes several Agents executed as concurrent parallel processes.
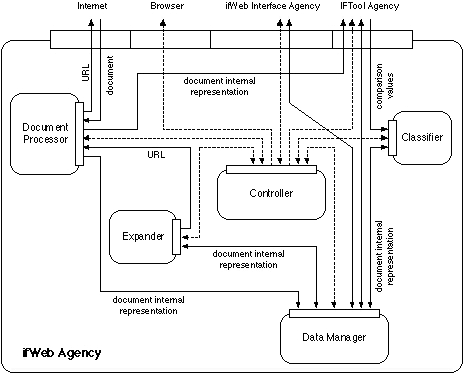
The Document Processor Agent requires
from the Network through an URL the retrieval of a specific document;
when the document is retrieved it extracts the information about
its structure and its content which are used in order to build
the document internal representation.
ifWeb considers only HTML documents.
The analysis of these documents is performed by a syntax direct
parser for the HTML (Data Type Definition) format and moreover
it includes segmentation, stop list deletion, stemming, contextual weighting,
and compression. The document internal representation produced
is then sent to the IFTool Agency for comparison with the user
model. The Classifier Agent receives the result of the comparison
performed by the IFTool Agency and classifies the document in
one of the three categories 'interesting', 'not-interesting'
or 'indifferent', on the basis of a user programmable criteria.
The Expander Agent manages the choice
about accessing or not the documents mentioned in the links (URLs)
specified in the currently analyzed document. In case of a positive
decision it forwards the request for access to the Document Processor
Agent, and the operation continues in analogous way.
The Data Manager Agent manages the shared memory and monitors
synchronization of access and consistency of data.
The Controller Agent coordinates and monitors
all activities performed by the various Agents and all the information
exchange with the user.
The strategies for the autonomous
navigation performed by ifWeb are based on the evaluation of how
much a link (URL) is considered promising for accessing
other documents which can be relevant to the user interests.
The computation of the degree
of promise of a link is executed by means of two parameters:
the first one is called expectation rate, and is a function
of the values obtained as results of the comparison carried out
with the user model and the consequent classification performed
on the currently analyzed document (i.e., the document containing
the URLs whose potential is considered for further navigation).
The second parameter, called confidence rate, is a function
of the values of the degree of promise of the documents previously
accessed on the path which concludes with the currently analyzed
document. In navigation support mode, all the promising link are
considered, whereas in search mode an hybrid best/breadth-first
search is adopted.
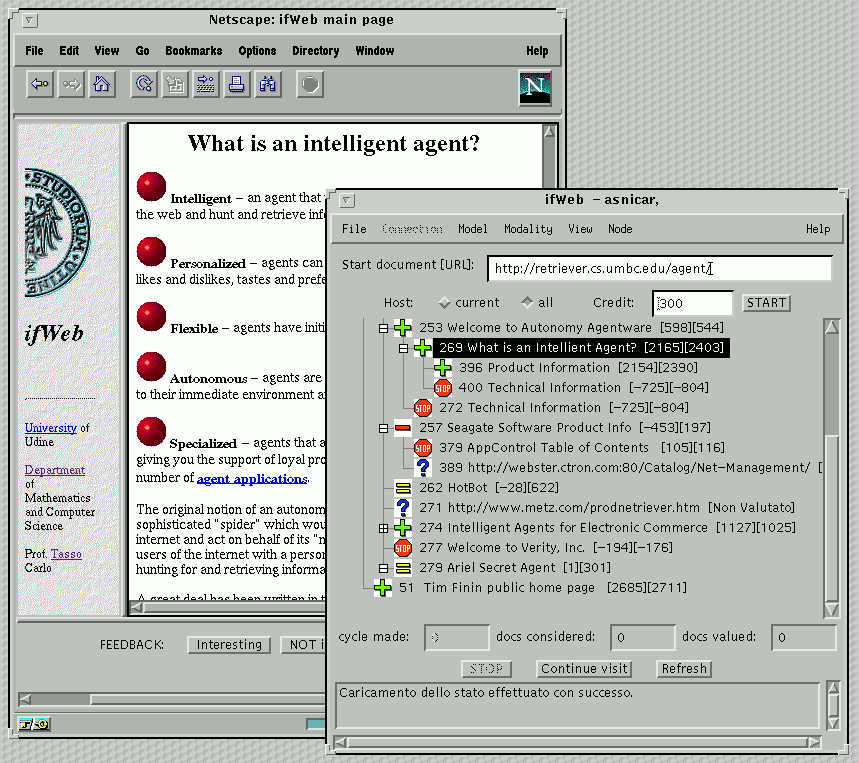
Figure 3 shows the user interface: it includes a normal browser window and a specific window managed by the ifWeb Interface Agency. This window is used for showing to the user the intermediate status and the results of the various analyses and for allowing the user to modify some system parameter. The documents are displayed in a tree-like structure, where the arcs correspond to hypertextual links. The various icons represent the result of the classification performed on the documents: '+' means 'interesting', '=' means 'indifferent', '-' means not-interesting, '?' means 'analysis not performed' (i.e. document not available), 'STOP' means that the Expander Agent has decided not to continue the analysis from that document. The user can easily modify the order of analysis, he can request the access to links which where considered non promising by ifWeb, he can exclude some document from navigation, and he can ask for display (through the browser) of a specific document in its original form. In the browser window, two specific buttons allow the user to provide his feedback on a document.
A specific evaluation activity has been carried out on ifWeb. The goals of the evaluation were:
The evaluation activity has been performed through real-time access to Internet: four subjects where using ifWeb having in mind a specific field of interest (usually their specific field of expertise). Each subject was carrying out 9 sessions with ifWeb. ifWeb was started with a user model obtained through (positive and negative) feedback on a limited set of documents (4-6). The model was later incrementally 'learned/refined' by ifWeb, thank to the feedback provided by the user. During each session ifWeb was working autonomously and, at the end of the session, it displayed the results to the subject. The subject was then requested to provide feedback, and to order the results according to his relevance judgment. The data collected at the end of each session were then used for computing two performance figures: ndpm [8] (a measure of the capability to order correctly the documents from interesting to not-interesting) and standard precision.
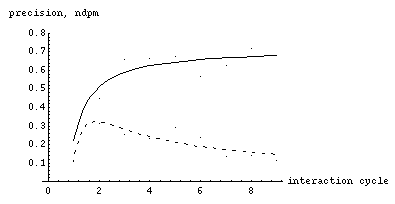
Figure 4 shows the results of this experimentation. After the initial session where ifWeb has a too limited knowledge of user preferences (and so results are not significant being mostly random), both the computed figures show that the system progressively improves its performance through the user feedback, both in terms of overall precision of classification (upper curve) and of capability to order correctly the documents according to their potential interest for the user (lower dotted curve).
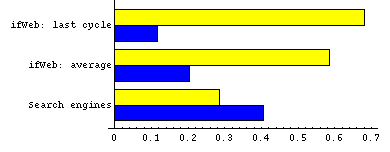
The comparison with standard search
engines has been specifically performed with AltaVista
and ExCite. More specifically: the most relevant keywords included in
the user model of ifWeb at the end of the 9 session experiment
described above, were submitted to the two search engines as query.
On the outcome, ndpm and precision were computed, according to
the relevance and order judgment provided by the subjects.
Figure 5 illustrates the results:
they show that ifWeb provides more precise results and better
ordering.
The ifWeb prototype is currently under further development. However, some conclusions can be already be drawn:
[1] M. Pazzani, J. Muramatsu, D. Billsus, "Syskill & Webert: Identifying interesting web sites", Proceedings of the 13th National Conference on Artificial Intelligence, 1996. http://www.ics.uci.edu/~pazzani/RTF/AAAI.html
[2] P. Edwards, D. Bayer, C. L. Green, T. R. Payne, "Experience with Learning Agents which Manage Internet-Based Information", Proceedings of the AAAI Spring Symposium on Machine Learning in Information Access, Stanford, March 1996. ftp://ftp.csd.abdn.ac.uk/pub/pedwards/MLIA.ps
[3] A. Moukas, "Amalthaea: Information Discovery and Filtering using a Multiagent Evolving Ecosystem", Proceedings PAAM96, The Practical Application of Intelligent Agents and Multi-Agent Technology, London, UK, April 1996. http://lcs.www.media.mit.edu/~moux/papers/PAAM96/PAAM96.html
[4] M. Balabanovic', "An Adaptive Web Page Recommendation Service", accepted in First International Conference on Autonomous Agents, Marina del Rey CA, February 1997. http://www-diglib.stanford.edu/cgi-bin/WP/get/SIDL-WP-1996-0041
[5] M. Wooldridge, N. R. Jennings, "Intelligent Agents: Theory and Practice", Knowledge Engineering Review, Vol 10(2), pp. 115-152, 1995. http://www.doc.mmu.ac.uk/STAFF/mike/ker95/ker95-html.html
[6] M. Minio, C. Tasso, "User Modeling for Information Filtering on INTERNET Services: Exploiting an Extended Version of the UMT Shell", Proceedings of the Fifth International Conference on User Modeling, Hawaii, January 1996. http://www.cs.ju.oz.au/bob/um96-workshop.html
[7] G. Brajnik, C. Tasso, "A
Shell for Developing Non-Monotonic User Modeling Systems",
Int. J. Human-Computer Studies 40, pp. 31-62, 1994.
[8] Y. Y. Yao, "Measuring
Retrieval Effectiveness Based on User Preference of Documents",
Journal of the American Society for Information Science, 46(2),
pp. 133-145, 1995.
http://www.dimi.uniud.it/~ift/um97/positionp.html
A postscript version of this paper is available at http://www.dimi.uniud.it/~ift/um97/positionp.ps.Z