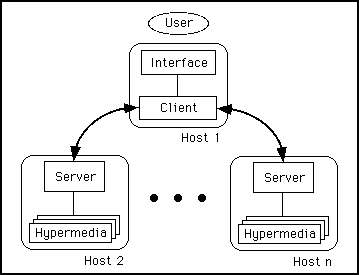
Fig. 1 - The usual architecture
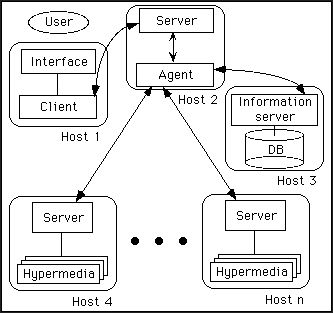
Fig. 2 - The agent enriched architecture
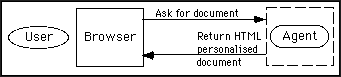
Fig. 3 - The agent acting as server
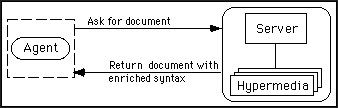
Fig. 4 - The agent acting as client
Oreste Signore, Rigoletto Bartoli, Giuseppe Fresta
CNUCE - Institute of CNR - via S. Maria, 36 - 56126 Pisa (Italy)
Phone: +39 (50) 593201 - FAX: +39 (50) 904052
E.mail: {O.Signore,R.Bartoli,G.Fresta,}@cnuce.cnr.it
Abstract: As WWW users can give different relevance to various types of information, we developed a very simple "agent" that parses the document supplied by the server taking appropriate actions based on the user profile, and returns the document tailored to user's interests. The agent supports filtering of links and of semantically tagged parts of the document, as well as multi-ended and weighted links. The hypertext provider must just use a very simple HTML extension, that allow to semantically tag paragraphs and links, and does not affect the actions taken by an ordinary HTML browser.
keywords: World Wide Web, intelligent agents, user profile, weighted links, multi-ended links, user modeling, dynamic content presentation, dynamic link structure
The explosion of hypertext applications and the popularity of the World Wide Web very much give the feeling that we found the "magic" solution to make information accessible to everyone. However, the excess of information results in a waste of time, while users would like to get only the relevant information, and to be able to discover, at first glance, if an information node or a link can be of interest. Therefore, information producers must carefully design pages to be able to capture the right target. In the following, we will present a simple but effective solution.
A main issue in hypertext design is the distinction between the extensional (or explicit) and the intensional (or implicit) links. While the first ones are explicitly stored in the hypertext nodes, the last ones are deduced from the context. Extensional links can be interpreted essentially as structural links, and therefore implement static and pre-defined associations between nodes. On the contrary, intensional links constitute the real richness of any hypertext, as they can be seen as an emulation of the human mind's association mechanism. To make an example, the botanical entities "Prunus spinosa" and "Malus baccata" are related by the fact that both belong to the order of "Rosales". However, this kind of association is relevant only if we are concerned with the characteristics common to genera and species belonging to the same family or order. A totally different association can link species living in similar geographic regions or climates, as well as having special usage or properties when combined, or flowering in the same period. It comes firstly that the number of possible links can be high, and secondly that the links are of different types, and therefore are of different relevance to the user according to his/her interests. To some users, certain links can be totally irrelevant. Links referring to glossary, whose relevance is null to a skilled user, are a typical example. Obviously, even the nodes are of different types, and their content should conform to the user's specific interests. Finally, we must consider that a good practice in hypertext design is to not overload the nodes with too much information and too many links. A typical user will just display, but not carefully read up to the very end, nodes containing too much information. The presence of too many links in a page can disturb, especially if some of these lead to non relevant nodes. All these considerations lead to the idea of having nodes and links that dynamically conform to the user profile, intended as a specification of the types of links and information he/she is interested to. Another important aspect is constituted by the need of implementing multi-ended links: when a single anchor point in an information node is connected to several other information nodes, the user should have them displayed, to choose the most interesting for his/her purposes. All these issues are described in more detail in [Signore95a], [Signore95b] and [Signore96].
The agent is a software intermediary between the user and the hypertext. If we agree with the estimate which considers that at least 99% of available data are not interesting to at least 99% of users, we can easily understand as the most relevant problem is helping the user in filtering the relevant information. We must also recognise that it would appear unfeasible to develop a solution that would heavily impact with the current hypertext structure or would not use a standard HTML browser. Keeping in mind that the user can give different relevance to various types of information, we developed a very simple "agent" that can mask or visualise the different types of links depending on their relevance to the specific interests stated by the users. Would the designer give a precise semantics to the various paragraphs contained in the document, the agent can drop out some of them, if they are non relevant to the user. Therefore the main goal of the agent is supporting:
Figure 1 shows the usual architecture of a hypermedia system. In its first implementation, the agent is implemented in the architecture shown in Figure 2. In both cases the modules are shown as residing on different hosts just for clarity and to emphasize the possibility of implementing a completely distributed architecture, but they could reside on the same host. The Information server in Figure 2 stores the user profile, stating the type of information the user is interested to, and the degree of interest. The agent combines the weight stored in the user profile with the weight assigned by the designer and compares it with a threshold value stated by the user. All the weights are numbers in the range [0,1]. Quite obviously, the user can modify his/her profile at will. The agent acts as server (Figure 3) for requests submitted by the users willing to access the hypertext, and as client towards the server managing the hypertext. Once the agent receives the user request, it accesses a database storing the user profile. Afterwards, it acts as a HTTP client, gets the document, parses it taking appropriate actions based on the user profile, returns to the user the document tailored to his/her interests (Figure 4).
Fig. 1 - The usual architecture
Fig. 2 - The agent enriched architecture
Fig. 3 - The agent acting as server
Fig. 4 - The agent acting as client
Component Syntax
paragraph <p type="paragraph type"> paragraph_text </p>
link <simple link> | <multilink>
simple link <a href="http://server/pathdocument" type="link type">
Text identifying the link word(s) </a>
multilink <a href="http://server/pathdocument1" type="link-1 type"
title="associated word-1"
href="http://server/pathdocument2" type="link-2 type"
title="associated word-2"
...
href="http://server/pathdocumentN" type="link-N type"
title="associated word-N">
Text identifying the link word(s) </a>
It is easily seen that a standard Web browser would ignore the additional attributes: the type attribute for paragraph and link will be simply skipped, while for multi-ended links (repeating attribute) only the first one would be considered. The presence of the link weight and threshold value, that the agent will consider in preparing the document to be showed by the browser, will reduce the number of links the user will perceive. In the present implementation (about two years old, anyway) for each link type both the author and the user will specify the relevant weight. Their values will be combined by the agent, that will finally find the link weight, to compare with the threshold value. As a consequence, depending on the user's profile, some links can be masked. Typical examples are the glossary links, that can be omitted for users skilled in the field, while some in depth references could be transformed into plain text. In more detail, irrelevant paragraphs or links, as well as links whose weight is less than the threshold value, are omitted. Multiple links are managed emphasising the text identifying the link words, followed by a parenthesis enclosing all the associated words related to a link whose weight and type can be of interest for the user. In all cases the additional attributes are removed, and the document is returned according to the standard HTML syntax.
The implemented agent is a simple and effective tool enablig the designer to write HTML pages that can be adapted to different users, so easily managing the cases of reserved information, different image quality, multilingual documents, and so on.
A new version of the agent is currently under development. In this new version, written in Java, the filtering can take place at the server site and at the client side, so that the user can modify the content of the displayed page without accessing the server again. In addition, the grammar will be SGML compatible, paragraphs can have several semantic weighted types and support of link weights is more sophisticated.
| [Signore95a] | Signore O.: Issues on Hypertext Design, DEXA'95 - Database and Expert Systems Application, Proceedings of the International Conference in London, United Kingdom 4-8 September 1995, Springer Verlag , ISBN 3-540-60303-4, pp. 283-292 |
| [Signore95b] | O. Signore,Modelling Links in Hypertext/Hypermedia, inMultimedia Computing and Museums, Selected papers from the Third International Conference on Hypermedia and Interactivity in Museums (ICHIM'95 - MCN'95), October 9-13, San Diego, California (USA), ISBN 1-88-5626-11-8, 198-216 |
| [Signore96] | Signore O.: Exploiting Navigation Capabilities in Hypertext/Hypermedia, HICSS-29 Annual Hawaii International Conference on System Science, Maui, Hawaii - January 3-6, 1996, ISBN 0-8186-7327-3, ISSN 1060-3425, pp. 165-175 |