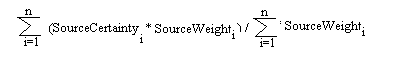
Eftihia Benaki, Vangelis A. Karkaletsis, Constantine D. Spyropoulos
National Centre for Scientific Research (N.C.S.R.) "DEMOKRITOS
Institute of Informatics & Telecommunications
15310 Aghia Paraskevi, Athens, Greece
tel. +30 1 6513110
fax. +30 1 6532175
{eben,vangelis,costass}@iit.nrcps.ariadne-t.gr
Abstract: This paper introduces user modeling into the process of information extraction. It presents the user modeling prototype (UMIE) that we developed in the context of the Information Extraction (IE) research project ECRAN. UMIE takes as input information extracted from corpora and adapts it according to the user's interests in domain categories. A demo Web page has been designed for UMIE and is now being tested. The Web page will be used for the evaluation of UMIE by real users.
keywords: user modeling, information extraction, WWW
Text-based information systems deliver to users information retrieved/ filtered/ extracted from texts. Information retrieval systems, based on the user's query, retrieve relevant documents from a relatively static set of documents. Information filtering systems examine a dynamic stream of documents and display only those which are relevant to the keywords profile of a user. Information extraction systems extract facts from documents in a domain. The extracted facts fill the pre-defined templates for the specific domain.
Today's information overloading often makes information systems ineffective. User modeling helps to deliver to the user information according to his needs, interests and/or expectations. User modeling techniques have already been integrated into information retrieval (Croft and Thompson, 1986, Brajnik et al, 1990) and information filtering systems (Brajnik and Tasso, 1994, Kay,1995, Orwant, 1993). However, they have not been integrated so far into information extraction systems.
The objective of this work is to examine the integration of user modeling techniques in the IE process. In the context of the IE research project ECRAN, we developed UMIE (User Modeling in Information Extraction) prototype (Karkaletsis et al., 1996), a user modeling component that creates and stores user models and adapts the extracted information according to these models.
Among the ECRAN partners, there is SIS (Smart Information Systems), a german company that provides its clients with news that interest them. SIS sends company news to the ECRAN IE system. The extracted facts are then adapted by UMIE. Discussing UMIE with SIS, we decided to create a Web demo-page through which users would interact with UMIE. Different users, even some of SIS's clients will run UMIE and give feedback and comments. We have already implemented a first version of UMIE's Web page, which is currently being tested.
In ECRAN we analysed data about the company news domain and defined the domain and user knowledge as well as mechanisms (acquisition mechanism, consistency maintenance, explanation) to manipulate this knowledge.
Domain. The domain knowledge consists of different domain categories, organised in a single-rooted hierarchical knowledge base. In the company news domain, for instance, such categories are "management successions", "joint ventures", "company results" and so on. Each domain category corresponds to a different template and the slots of the template define the attributes of the category. For instance, attributes of the "management successions" category are the management post, the company, the person who is vacating the post and so on.
Stereotypes. Stereotypes are groups of users which share the same interests according to a set of criteria (Rich, 1983). A criterion in the company news domain is the department of users. A user belonging in the management department is typically interested in "management successions", "manpower planning", "joint ventures", "mergers" and so on. Stereotypes are organised in a single-rooted hierarchical knowledge base. A user does not cease to belong in a stereotype since the triggers of the stereotypes are facts that do not change. Stereotypes do not change over time.
User models. User models are stored in a database at the end of each session and retrieved at the beginning of a new one. Apart from the user's name and the stereotypes he belongs to, the user model contains the domain categories along with a rating that shows if the category is interesting/ not interesting/ indifferent for the user and a confidence factor that indicates how strongly UMIE believes this rating. Indifferent categories are the ones for which UMIE has none or little knowledge whether they are interesting or not interesting. For each interesting category there may be some specific attribute values in which the user is not interested. For each not interesting category there may be some specific attribute values in which the user is interested.
Translation rules. The translation rules match the user's interests with the filled templates. In other words, they locate the filled templates requested by the user and filter the information of these templates according to the user model. The filled templates requested by the user are the ones that belong to the domain categories that interest him. The information of these templates can be filtered according to the user's specific requests on the attributes values.
To initialise user models the user optionally answers some questions about himself and his answers classify him under one or more stereotypes. The stereotypes that apply to him provide only interesting domain categories and therefore initialise the rating and the confidence factor for them. To enhance the initial knowledge, a set of sample documents, a few from each domain category are used. Each document is attached with a rating (default value=indifferent). The user may change the rating value to interesting/ not interesting. The final document rating values are used to increase or decrease the confidence factor for each category.
After initialising the user model, UMIE presents the user the information of the filled templates in a document-like form (canned text generation is used). These documents are classified in three different "baskets". For instance, the documents belonging in an interesting category C are classified in the "interesting" basket (default rating value= interesting). The user may change the document ratings to not interesting/ indifferent. The final document rating values may increase or decrease the confidence factor for category C. The same happens with the indifferent and not interesting categories.
The user can also state explicitly his interest/ indifference/ disinterest in the domain categories (Appendix, Screendump 2). Explicit information increases or decreases the confidence factor of the domain categories. The user can also explicitly specify the values of one or more of the categories attributes. For example, he can specify that he is interesting in management successions concerning chairmen (management post = chairman) .
Each of the sources of information (feedback to sample documents, stereotypical knowledge, feedback to resulted documents, explicit statement) changes the confidence factor with a different weight, according to its importance. Stereotypical knowledge is the least important source while explicit statement is the most important one. A (not) interesting category can become indifferent if its confidence factor is (more) less than a certain threshold very close to 0.0.
A simple function is used to update the confidence factor of a domain category each time new information arrives from a source. The function UMIE currently uses is the following:
The table that follows shows the weights and the certainty of each source of information.
|
|
| ||
To define function F, let INT be the amount of interesting
documents of category C, IND the amount of indifferent documents
of C and NOT_INT the amount of not interesting documents of C.
For each category C, function F is as follows:
(INT*1 + IND*0 + NOT_INT*(-1)) / (INT+IND+NOT_INT)
Inconsistencies may be explicitly derived from negative assumptions. For example, the assumptions "User X is interested in news about dividends" and "User X is not interested in news about dividends" raise a contradiction. UMIE handles each domain category once in a user model. A domain category is interesting, not interesting or indifferent for the user. It cannot be, for example, both interesting and not interesting. Negative feedback can be given to an interesting domain category, but this does not imply that the category will be in the user model again with a not interesting rating. The negative feedback will just decrease the confidence factor of the interesting category.
Inconsistencies may also be implicitly derived from contradictory assumptions. Being interested in a domain category of UMIE does not imply that you are not interested in some other domain category(ies). Therefore, UMIE does not face such implicit contradictions.
UMIE's explanation mechanism aims to answer questions of two forms: "Why did you present me this document?" and "Why is this domain category in my model with such a rating?".
Documents are presented because they belong to a category that exists in the user's model. Users can see a picture of their model. They can see the categories in which they are currently interesting, not interesting or indifferent. If a user is interested in category C and document d belongs to category C, the user can understand why d is presented as interesting.
UMIE does not currently answer questions of the second form. This is planned to be done in the near future, using the sources from where the rating of a domain category was derived.
In Section 2, we defined the formal models for the domain and user knowledge. Domain knowledge is stored in the domain knowledge base, stereotypical user knowledge is stored in the stereotypical knowledge base, user models are stored in the user models database and the translation rules are stored in the translation rules knowledge base.The IE database contains filled templates which are the result of the IE process. UMIE includes two main modules, The User Model Manager Module (UM) and the Translation Manager Module (TM).
The User Model Manager module is responsible for the following functions:
The Translation Manager module is responsible for the following functions:
We have implemented a first version of the Web page for testing UMIE with real users. UMIE is placed on a Web server, which serves multiple users, the clients. A client can be any Web browser. The server opens a socket and waits for the clients to connect to it.
A sequence of HTML documents have been created containing Java applets. As soon as the first of these HTML documents is loaded on the client's site, the client is connected to the server via a socket connection. Java applets communicate input from the client to the server and information from the server to the client via the client's socket connection. The socket connection of each client with the server ends when the client asks to terminate his interaction with the server.
A client can be a new one or an old one known to the server from a previous interaction. A client is identified by his name. The server stores and updates a database of the user models of the clients that have interacted with it. During each interaction the client's model is retrieved from the database or created and is kept temporarily at the server's memory until the client ends his interaction. The temporal model is then stored in the user models database.
Every time a client issues a request, his name and a number that corresponds to his socket connection are used to identify his temporal model. The server follows the First In First Out approach to answer clients requests. In cases of simultaneous requests, the first client connected to the server is first considered.
If a serious prolem halts the server the worst that could happen is that clients will lose their temporal models. The previous version of their model, if any, is safely stored in the user models database.
We are currently testing UMIE with categories in the company news domain. We are using templates of "management successions" and we plan to use templates of "joint ventures" and "company results" in the near future. We also intend to use other functions that update the confidence factor, work on the automatic inference of some attribute values and improve the explanation mechanism. The integration of the domain ontology used during information extraction with the domain knowledge base used by UMIE, is another issue that we will examine.
During the initialisation of a user's model, UMIE allows him to obtain the profile of another user with similar tastes ("similar user"). For instance, if a user X states that he has the same interests with user Y, user X's model is initialised with a copy of user Y's model. This is a rather simplistic approach. That's why we plan to examine issues such as the automatic identification of users with "similar tastes" and the grouping of "similar users" in communities (Orwant, 1993). Finally, we plan to consider other ways to acquire knowledge about the user, such as the times and the frequency he visits UMIE.
Brajnik,G., Guida,G.,Tasso,C., (1990): User modeling
in Expert Man-Machine Interfaces: A case study in Intelligent
Information Retrieval, in IEEE Transactions on systems, man,
and cybernetics, 20:166-185
Brajnik Giorgio and Carlo Tasso, (1994): A shell
for developing non-monotonic user modeling systems in International
Journal of Human Computer Studies, 40:31-62
Croft,B. and Thompson,R., (1986): An overview
of the IR Document Retrieval System, in Proceedings of the
2nd Conference on Computer Interfaces and Interaction for Information
Retrieval
Karkaletsis, E., Benaki, E., Spyropoulos, C., Collier,
R., (1996): D-1.3.1: Defining User Profiles and Domain Knowledge
Format, ECRAN
Kay,J., (1995): The um toolkit for Cooperative
User Modeling, in User Modeling and User-Adapted Interaction,
4:146-196.
Jon Orwant, (1993): Doppelganger Goes to School:
Machine Learning for User Modeling, MSc thesis at MIT
Rich, E., (1983): Users are individuals: individualising
user models in International Journal of Man-Machine Studies,
18:199-214

Screendump 1: Feedback to sample documents
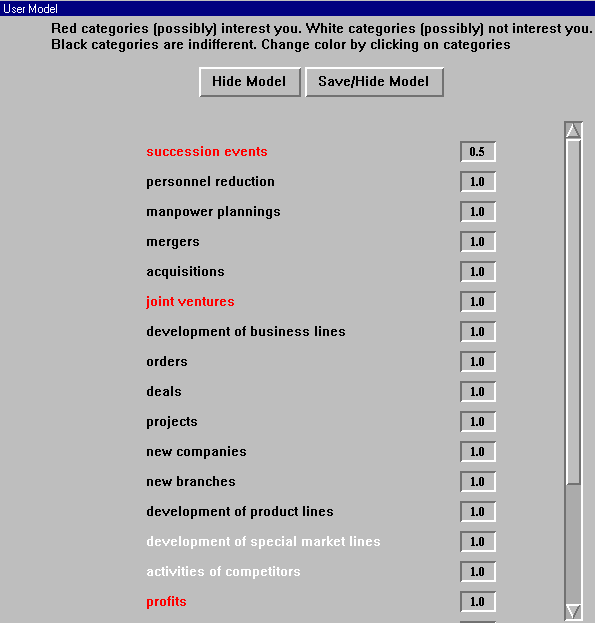
Screendump 2: Explicit statement