Jie Chi YANG, Kanji AKAHORI
the Center for Research And DeveLopment of Educational technology (CRADLE),
Tokyo Institute of Technology
2-12-1 O-okayama, Meguro-ku, Tokyo, 152, Japan
Tel: +81-3-5734-3233, Fax: +81-3-5734-2995
E-mail: yang@cradle.titech.ac.jp, akahori@cradle.titech.ac.jp
Abstract: This paper describes the development of a computer assisted language learning (CALL) system for learning of Japanese writing using natural language processing (NLP) techniques. This system could be used for writing to learn Japanese passive voice on the World Wide Web (WWW). To investigate the error types when writing in passive voice of Japanese language by foreign students, the authors conducted a test and took a questionnaire survey. From this investigation, the authors classified the error types of Japanese passive voice into 12 categories, 65 kinds and 228 errors. This classification will be used for error analysis which deals with the implementation of the system. In this system, the authors use NLP tools (including Morpheme analyzer and Syntax analyzer) and then add the error analysis and the feedback processing part to the system. This system thus enables the learner to key in sentence freely, can detect the error in typed sentence (sentence key in by learner) and gives the adequate feedback messages back to the learner. Furthermore, the authors propose the mechanism of correction by learner which allows the learner to correct the typed sentence by herself/himself, and allows the learner to realize that what error she/he has made. This mechanism can be considered as a supplement to the prediction of the system, and as an improvement in the effectiveness of current CALL system.
The effectiveness of CALL system have been made obvious by many researchers [4][7]. But it has the weakness that learner can not key in target language's sentence freely in current CALL system, particularly in computer assisted writing learning system. The learner just accepts the information which follows the instruction of curriculum which is pre-installed in the computer. Therefore, it can not be said that these type of systems are totally interactive. Due to this reason, more and more research [1][3][10] on NLP techniques in CALL system are being conducted. Research [2][5][9] on error analysis of writing learning system has been particularly improved with the excellent experiment result [6] in the robustness of NLP.
In CALL system, the analysis of the typed sentence is a must in order to allow learners to phrase their own sentences freely without following any pre-fixed rules. Therefore, we used NLP tools in order to analyze typed sentence.
Unfortunately, almost all of the grammar theories and the techniques of NLP that have been proposed until now can just analyze grammatically correct sentences. However Japanese language learners who use the CALL system are most likely to key in ill-formed sentences. Thus we can either add the error analyzer to the current unrectified NLP tools, or we can rectify NLP tools to correct this problem. In this study, we take the former approach. However, it was faced with the problem not to obtain the correct morpheme or part of speech of the word. It is difficult to determine the correct morpheme even the grammatically correct sentence because the sentence in Japanese is written continuously without any space1. Therefore, in case of ill-formed sentence, it will be interpreted as grammatically correct sentence. The incorrect morpheme will be obtained by using currently available NLP tools. For example, the correct sentence with correct morpheme "Jyon san wa kaku san ni nagura re mashita (John was hit by Mr. Kaku)." will be analyzed as "Jon san wa kaku san nina kura re mashita (John was turned over by Mr. Kaku?)." if the correct word "naguraremashita" is typed as the incorrect word "nakuraremashita". That is why the present system has been developed. The present system can obtain the correct morpheme even if the ill-formed sentence is typed.
In our system, we have used an approach that predicts the structure of ill-formed input, and then write them into the system for the purpose of error analysis. In other words, first comes the investigation for the possible structure of error sentences in passive voice, which is followed by making of rules to decide the correctness of sentences.
This paper describes a CALL system using NLP techniques which can solve the weaknesses of the current CALL system. The present system allows the learner to key in sentence freely, and can detect the errors of the typed sentence and gives the adequate feedback messages to the learner, which can be used for learning writing of Japanese passive voice on any WWW browser.
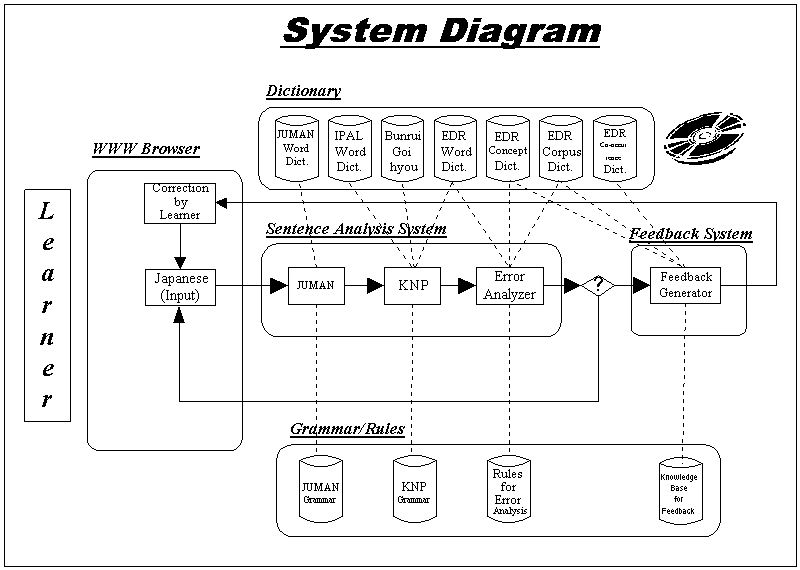
Figure 1 shows the diagram of the system. The system consists of the interface, i.e., WWW browser, the sentence analysis system, the feedback system, the dictionary, and the grammar/rules. The sentence analysis system includes morpheme analyzer (JUMAN 3.0), syntax analyzer (KNP 1.1) and error analyzer. The NLP tools JUMAN and KNP were developed by Nagao Laboratory, Kyoto University, Japan. These tools can analyze only grammatically correct Japanese sentences. The feedback system includes feedback messages generator, knowledge database, and all histories of learner during operating the system. Besides that, the electronic dictionary used in the system is EDR1.52 , IPAL3 , and Bunrui goi hyou4.
When this system is used, in the beginning, the registration such as name and history of Japanese learning of the learner is required. After the registration, the learner operates this system as per the instructions written on every web page. The learning page consists of many pictures which can be selected by the learner. When the learner chooses one of them, the large picture of the selected one and the text box will appear on a new page. Then the learner can look at the visual and key in the Japanese sentence with passive voice to the text box below. The text can be typed in both kanji or kana of Japanese language, as this is the usual input method of most Japanese word processor. The system thus gives the adequate feedback messages to the learner according the typed sentence if any error is detected.
The flow of the system:
The information of errors will be sent as an error ID from the sentence analysis system to the feedback system. The adequate feedback messages will be given according to the error ID. In this system, the authors propose the mechanism of correction by learner which allows the learner to correct the sentence by herself/himself, and allows the learner to realize that what error she/he has made. The correction by learner means that when the error is detected by the error analyzer, there will be no answer given back to the learner, but instead, the feedback messages according to the typed sentence will be shown. The learner can either read the feedback messages and correct the typed sentence instantly or she/he can refer some grammar items about her/his error and corrects the sentence later. The feedback message becomes more detailed with every correction. For example, if there is an error about the conjugation of verb, then the feedback message like "there is an error in the verb" and some links like "the table of verb", "the practice of conjugation of verb", "what is passive voice", and so on, will appear on the bottom of the message. The learner then can refer to these grammar items and corrects the sentence by herself/himself. Of course the sentence can be corrected directly right after reading the feedback messages.
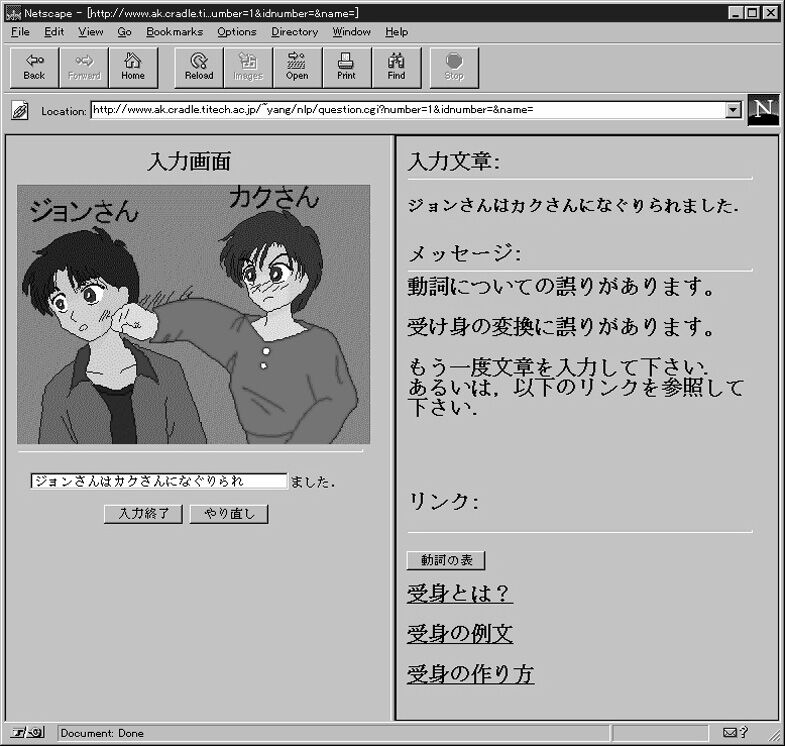
Figure 2 illustrates the feedback messages with the wrong conjugation of verb in passive voice.
In this paper, the authors describe the development of a NLP based CALL system for the purpose of learning the passive voice in Japanese language. This system allows the learner to key in Japanese sentence freely and can detect the errors of the typed sentence beside providing the learner with adequate feedback information. The learner can use this system to learn Japanese language anywhere and anytime because this system runs on any WWW browser. This approach can thus be considered as a new means in learning language (especially Japanese language in our case) in the future. As described earlier, we can not use the current NLP tools as it is. Instead, we have to deploy the error analyzer in order to analyze the ill-formed input. In our system, however, we use the approach that predicts the structure of ill-formed input, and then write them into the system for error analysis. In order to do this, the authors conducted a survey to investigate the error types in writing the passive voice of Japanese language by foreign students. Although this is a troublesome work, it does help in gathering the error data which will be used for error analysis later.
We plan to enrich the present system, e.g., error corpus extension, different feedback message for different individual and a more flexible rules for error analysis by using the EDR concept dictionary.