Elisabeth André, Thomas Rist and Jochen Müller
German Research Center for Artificial Intelligence (DFKI)
Stuhlsatzenhausweg 3, D-66123 Saarbrücken, Germany
Email: {andre,rist,jmueller}@dfki.uni-sb.de
Abstract: A growing number of research projects both in academia and industries have started to investigate the use of animated agents in the interface. For educational systems on the web, they are a promising option as they make presentations more lively and appealing, and even allow for the emulation of conversation styles known from personal human-human communication. In this paper*, we develop an operational approach for the automated generation of interactive WWW presentations given by a life-like presentation agent. The approach relies on a model that combines behavior planning with concepts from hypermedia authoring such as timeline structures and navigation graphs.
In the last few years, animated characters in the interface, either based on cartoon-style drawings [11], real video [8], or geometric 3D-models [12, 4, 6]) have become increasingly popular. For educational systems on the web, they are a promising option as they make presentations more lively and appealing, and even allow for the emulation of conversation styles known from personal human-human communication. Among other things, they can be employed to:
With the advent of web-browers which are able to execute programs embedded in web-pages, the use of animated characters for the presentation of information over the web has become possible. A web-presentation can now comprise dynamic media such as video, animation and speech, all of which have to be displayed in a spatially and temporally coordinated manner. Such a coordination is needed for dynamic presentations in which a life-like character points to and verbally comments on other media objects, such as graphics, video clips, or text passages. The principle is to pack into a web-page and ship to the client:
Unlike other approaches, e.g., Ball [5], we primarily employ life-like characters for presenting information. We don't allow for communication with life-like characters via speech in order to avoid many problems resulting from the deficiences of current technology for the analysis of spoken language. Nevertheless, the user has the possibility to influence the course of the presentation by making specific choices while it is run. The novelty of our system is that presentation scripts and navigation structures are not stored in advance, but generated automatically from pre-authored document fragments and items stored in a knowledge base.
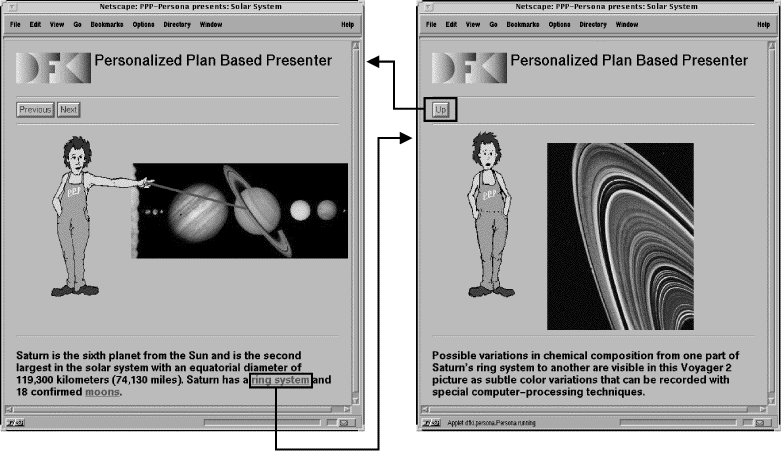
Fig. 1 shows an example. Suppose the student wants to get some information concerning the planets of the solar system. To comply with the student's request, the Persona provides a short introduction for each planet. To give the student the possibility to ask for more information, several items in the text are made mouse-sensitive. Clicking on one of these items will lead to the insertion of a subscenario. For instance, if the student clicks on the ring item while Saturn is introduced, the Persona will interrupt the current presentation and run a script with information concerning Saturn's ring system. After that, it will continue with the main script.
To generate such presentations automatically, we build upon our previous work on the automated planning of presentation scripts for presentation agents (cf. [3]), and extend this work for interactive web-presentations. This extension will be described in Section 3. In the following section, we first describe how we represent the information from which our web-presentations are generated.
For the application presented in the introduction, we start from a database which comprises both information about the domain and information about documents. A similar approach has also been used for the generation of adaptive hypertext, see e.g. [7].
Domain information is represented in terms of objects and relations between them (cf. Fig. 2). For example, in the ``Solar-System-Domain'' objects are planets, comets, asteroids etc. A type hierarchy is used to allow for hierarchically structuring domain representations. The set of domain relations may comprise, for example, a part-of relation to express that a certain planet belong to a certain solar system, or a diameter-relation which may hold between a number and a planet.
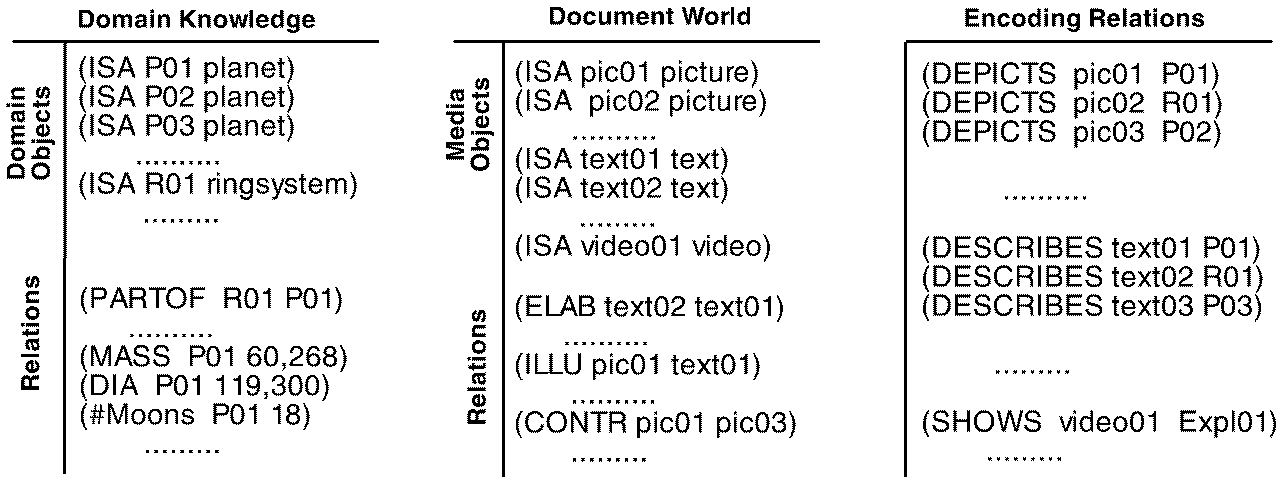
Similar, document information is represented in terms of media objects and relations between them. Media objects are pre-authored document fragments, e.g. a text paragraph or an illustration. Relationships between media objects represent what kind of communicative role a media object may play with respect to another media object in a presentation. For instance, a text paragraph may elaborate on an illustration.
Certainly, media objects serve to present domain information. To bridge the gap between domain information and media objects, we rely on a set of so-called encoding relationships. For example, if the database contains a picture of a certain domain object, then the connection between the two items can be represented by the relation (Depicts pic obj).
Our presentation model has two main ingrediants: A model which describes the behavior of the character, and a model for the description of hypermedia presentations.
What makes up a reasonable behavior for a character depends on a number of factors, such as the chosen metaphor, its purpose, and the conversational setting. As shown in the example above, our Persona is a cartoon-style human-like figure. Its primary purpose is to execute presentation acts, and interaction with the character is rather limited as it excludes speech input completely. Since we aim at a generic presentation agent, we are most interested in domain-independent actions. The current repository of such general actions comprises Presentation acts, Reactive behaviors on sensed events, Idle-time acts and Low-level navigation acts.
The Persona's behavior is coordinated by a so-called behavior monitor which determines the next action to be executed and decomposes it into elementary postures. These postures are forwarded to a character composer which selects the corresponding frames (video frames or drawn images) from an indexed data-base, and forwards the display commands to the window system.
An important characteristics of our web presentations is that they are not just played back, but have a branching structure which allows the user to choose between different possibilities to enrol it. That is the course of a presentation changes at runtime depending on user interactions. In this section, we will present a model for describing such interactive presentations.
Inspired by the Amsterdam Hypermedia Model [9], we represent web presentation by a collection of presentation units and a set of transitions specifying how to get from one presentation unit to the other.
A presentation unit is defined by a collection of media objects together with a presentation script. We assume that a presentation unit is a self-contained part of a presentation whose media objects are placed in time independently of media objects corresponding to other presentation units. Presentation scripts entail directions for the character concerning the presentation of media objects. They are represented by timeline diagrams which position all actions to be executed by the character along a single time axis.
Timeline diagrams enable us to describe the temporal behavior of a presentation in an intuitive manner, however, they provide no means of describing the control flow of interactions. Therefore, we combine timeline diagrams with state-transition graphs. That is timeline diagrams are used for describing the temporal behavior of single presentation units while state-transition graphs serve to describe the navigation structure of a presentation.
A state-transition graph is defined by a set of nodes and edges. With each node, we associate a presentation unit, and a default duration, usually the duration of the presentation unit. If a node is entered, the corresponding presentation script is run.
A transition from one node to another is made if one of predicates associated with the edges leading away from the node is satisfied or the default duration is over. Predicates usually refer to user interactions, such as clicking on mouse-sensitive icons in a presentation.
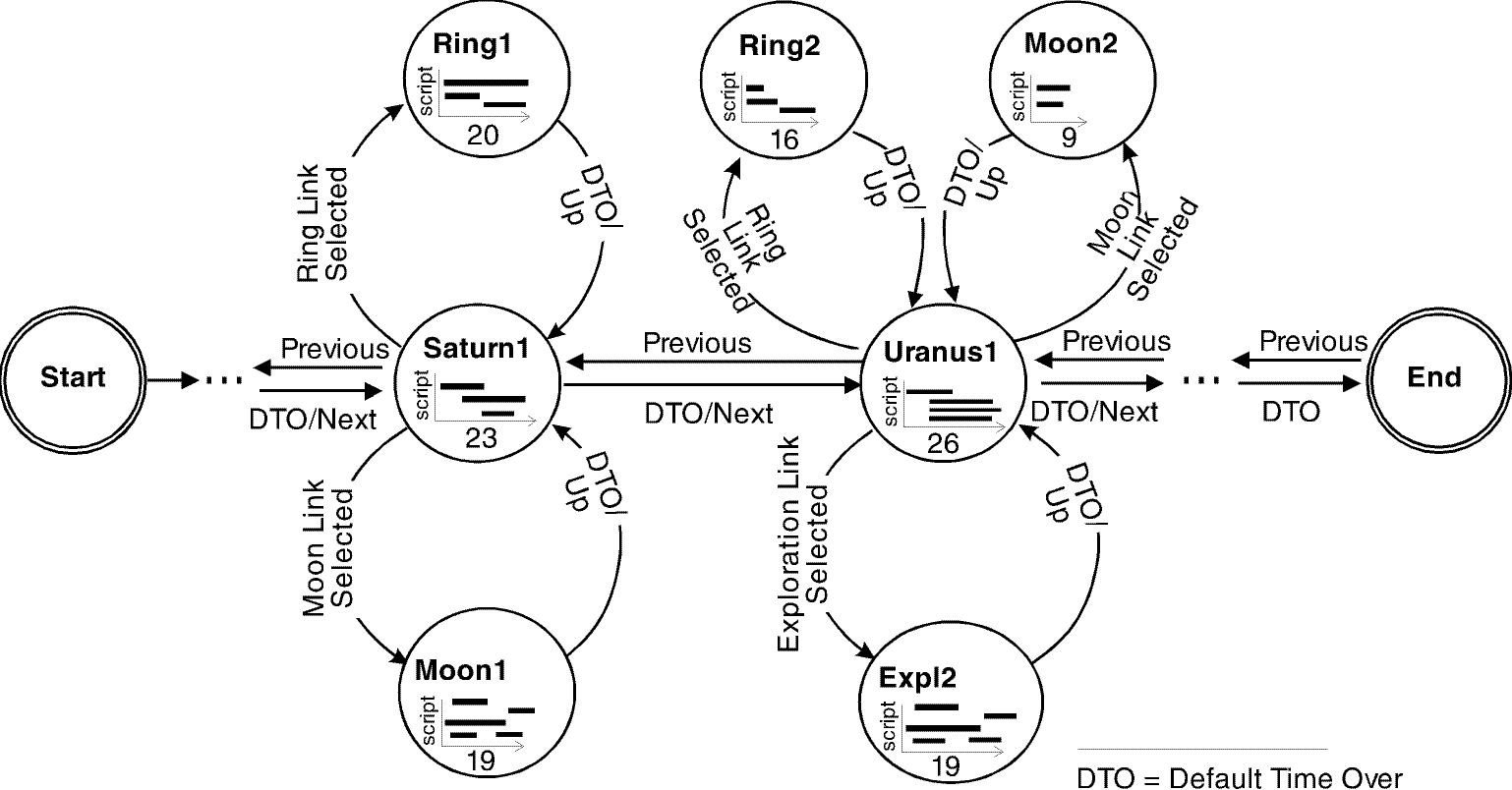
The concepts introduced above will be illustrated by means the example presented in the introduction. The navigation graph of this example is shown in Fig. 3. The presentation is started by entering the starting node. Since the default duration of this node is 0, the node for the first planet is entered immediately and the corresponding presentation script for the Persona is run. After that, a transition is made to the next planet node. Let's suppose the user clicks on the ring button while the Persona describes Saturn. As a consequence, the presentation is interrupted and the ring system script is played. That is the Persona now informs the student about Saturn's ring system. After that, the system returns to the saturn node and plays back the remaining parts of the script. After the default time of 23 time units has passed, a transition is made to the Uranus node. Here, again the user has the possibility to request for more information, e.g., about Uranus' moons. After the script for all planet nodes have been run, a transition is made to the end node.
In the last section, we have presented a model for describing interactive web presentations. However, the manual creation of navigation graphs and presentation scripts is tedious and error-prone. To satisfy the individual needs of a large variety of users, the human author would have to prepare a large number of presentations in advance and to hold them on stock. In the following, we will discuss how to automate the generation process. This process comprises the following steps:

To accomplish (1), we rely on our previous work in which we have
presented an approach for structuring non-interactive multimedia
presentations. The main idea behind this approach was to formalize
action sequences for sequences for composing multimedia material and
designing scripts for presenting this material to the user as
operators of a planning system. The effect of a planning operator
refers to a complex communicative goal (e.g. to provide information
about a planet) while the expressions in the body indicate which acts
have to be executed in order to achieve this goal (e.g., to show an
illustration and to describe it). The temporal behavior of these acts
is specified by a list of qualitative and metric constraints. Like
other authors in the Multimedia community, e.g. see
[10], we represent qualitative constraints in an
``Allen-style'' fashion (cf. [1]) which allows for the
specification of thirteen temporal relationships between two named
intervals, e.g. (Speak1 (During) Point2). Quantitative
constraints appear as metric (in)equalities, e.g. (5 ![]() Duration Point2).
Duration Point2).
The input to the presentation planner is a complex presentation goal, e.g., to present a set of planets. To accomplish this goal, the planner looks for operators whose header subsume it. If such an operator is found, all expressions in the body of the operator will be set up as new subgoals. The planning process terminates if all subgoals have been expanded to elementary production/retrieval or presentation tasks. The result of this process is a refinement-style plan which reflects the rhetorical structure of the presentation (see Fig. 4). For example, there is a sequence relationship between the single planet presentations and elaboration relationships between these presentations and the corresponding subscenarios. Furthermore, this plan specifies how the single parts should be temporally coordinated. For instance, the text and the corresponding illustration should be displayed at the same time.
After the planning process is completed, step (2) will be performed. That is the presentation is partitioned into self-contained units which will become nodes in the navigation graph. Obvious critera for the partioning are the available display space on the page as well as the temporal and rhetorical relationships between presentation acts. Furthermore it seems reasonable to separate optional from obligatory presentation parts. The same goes for presentation parts which are not directly related to each other, e.g., presentation parts describing different database entries.
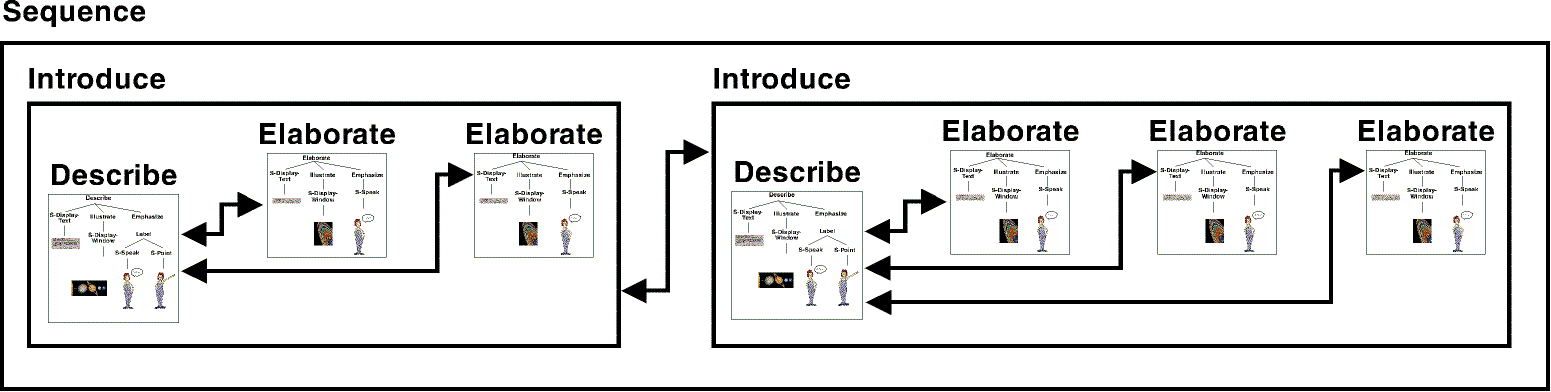
In the solar system example, the presentation parts corresponding to Illustrate and Emphasize are collected into one presentation unit because they refer to each other and temporally overlap. Since there is enough space on the page, S-Display-Text is assigned to this presentation unit as well. In contrast to this, all elaborations are realized by own presentation units because they are considered as optional. Finally, the two introductions are assigned to different presentation units since they refer to different matching offers which are described in sequence.
Fig. 5 shows how the single parts of the solar system presentation are grouped into presentation units. While the rectangles correspond to these units, the arrows correspond to hyperlinks.
Step (3) is the design of the navigation graph. Since each presentation unit corresponds to a node of the presentation graph, we only have to specify how to get from one node to the other. These conditions then correspond to the predicates associated with the edges of the navigation graph. For instance, to get from a scenario to an elaborating subscenario, a specific button has to be selected. If the presentation associated with the subscenario is over or the user clicks on a up button, the system returns to the main scenario. To jump back and forth between scenarios connected via a sequence relationship, the user may select a next or previous button resp.
The last step is the creation of the scripts for the presentation units. To accomplish this task, the system first collects all temporal constraints on and between the actions corresponding to a unit. After that, it determines the transitive closure over all qualitative constraints and computes numeric ranges over interval endpoints and their difference. Finally, a schedule is built up by resolving all disjunctions and computing a total temporal order (see [3]).
We have argued that the use of life-like characters are a promising option for educational systems on the web. In order to describe such presentations, we combined a behavior model for life-like characters with concepts from hypermedia authoring. Since the manual specification of such presentations would be too labour intensive and error-prone, we also showed how to automate this process. Our current prototype is able to generate both presentation scripts for life-like characters, and navigation structures to allow the user to dynamically change the course of a presentation at runtime.
We plan to extend our work on presentation agents along several directions. First of all, we intend to interleave the design of the discourse structure with the design of navigation structures. This method would have the advantage that presentations can be adapted to the current situation at runtime. For example, elaborations would only be planned down to the last detail if the user selects the corresponding buttons. Another idea is to employ more than one agent in a presentation. This extention would allow for different role castings, consider for example two experts discussing different aspects of a planet. A new line of research will be opened up with the dissemination of virtual worlds via the web, as life-like agents and so-called avatars will become the inhabitants of these worlds. While the audio-visual realization of these agents will be facilitated by the emerging VRML 2 standard, our technology may be used to have them perform presentation tasks.
This work has been supported by the BMBF under the grants ITW 9400 7 and 9701 0. The sample presentation was assembled from material found on the NASA/JPL web pages (see http://hiris.anorg.chemie.tu-muenchen.de/AAL/otto/solarsystem/). We would like to give credit to Calvin J. Hamilton who processed the image of the solar system.